"""
To try the examples in the browser:
1. Type code in the input cell and press
Shift + Enter to execute
2. Or copy paste the code, and click on
the "Run" button in the toolbar
"""
# The standard way to import NumPy:
import numpy as np
# Create a 2-D array, set every second element in
# some rows and find max per row:
x = np.arange(15, dtype=np.int64).reshape(3, 5)
x[1:, ::2] = -99
x
# array([[ 0, 1, 2, 3, 4],
# [-99, 6, -99, 8, -99],
# [-99, 11, -99, 13, -99]])
x.max(axis=1)
# array([ 4, 8, 13])
# Generate normally distributed random numbers:
rng = np.random.default_rng()
samples = rng.normal(size=2500)
samplesPython으로 작업하는 거의 모든 과학자는 NumPy의 힘을 이용합니다.
NumPy는 C 및 Fortran과 같은 언어의 계산 능력을 배우고 사용하기 훨씬 쉬운 언어인 Python으로 가져옵니다. 이 힘에는 단순함이 있습니다. NumPy의 솔루션은 종종 명확하고 우아합니다.
NumPy의 API는 라이브러리가 혁신적인 하드웨어를 활용하거나, 특수 배열 유형을 생성하거나, NumPy가 제공하는 것 이상의 기능을 추가하도록 작성되는 출발점입니다.
| 배열 라이브러리 | 기능 및 응용 분야 | |
 |
Dask | 분석을 위한 분산 배열 및 고급 병렬 처리를 통해 규모에 맞는 성능을 구현합니다. |
 |
CuPy | Python에서 GPU 가속 컴퓨팅을 구현해주며 NumPy와 호환되는 배열 라이브러리. |
| JAX | NumPy 프로그램을 부분적으로 변환하여 벡터화, GPU/TPU의 적시 컴파일을 제공하는 라이브러리. | |
 |
Xarray | 고급 통계 및 시각화를 구동하기 위하여 라벨링 및 인덱싱이 이뤄진 다차원 배열을 제공 |
 |
Sparse | Dask 및 SciPy의 희소 선형 대수와 통합되는 NumPy 호환 희소 배열 라이브러리입니다. |
| PyTorch | 연구 프로토타이핑에서 프로덕션 배포로의 경로를 가속화하는 딥 러닝 프레임워크입니다. | |
| TensorFlow | 기계 학습을 위한 엔드 투 엔드 플랫폼으로 ML 기반 애플리케이션을 쉽게 구축하고 배포할 수 있습니다. | |
| MXNet | 유연한 연구 프로토타이핑 및 생산에 적합한 딥 러닝 프레임워크입니다. | |
| Arrow | 열 기반 메모리 내 데이터 및 분석을 위한 교차 언어 개발 플랫폼입니다. | |
 |
xtensor | 수치 분석을 위한 브로드캐스팅 및 지연 컴퓨팅이 포함된 다차원 배열. |
 |
Awkward Array | NumPy와 유사한 관용어로 JSON과 유사한 데이터를 조작합니다. |
 |
uarray | 구현에서 API를 분리하는 Python 백엔드 시스템; unumpy는 NumPy API를 제공합니다. |
 |
tensorly | NumPy, MXNet, PyTorch, TensorFlow 또는 CuPy를 원활하게 사용하기 위한 Tensor 학습, 대수 및 백엔드. |
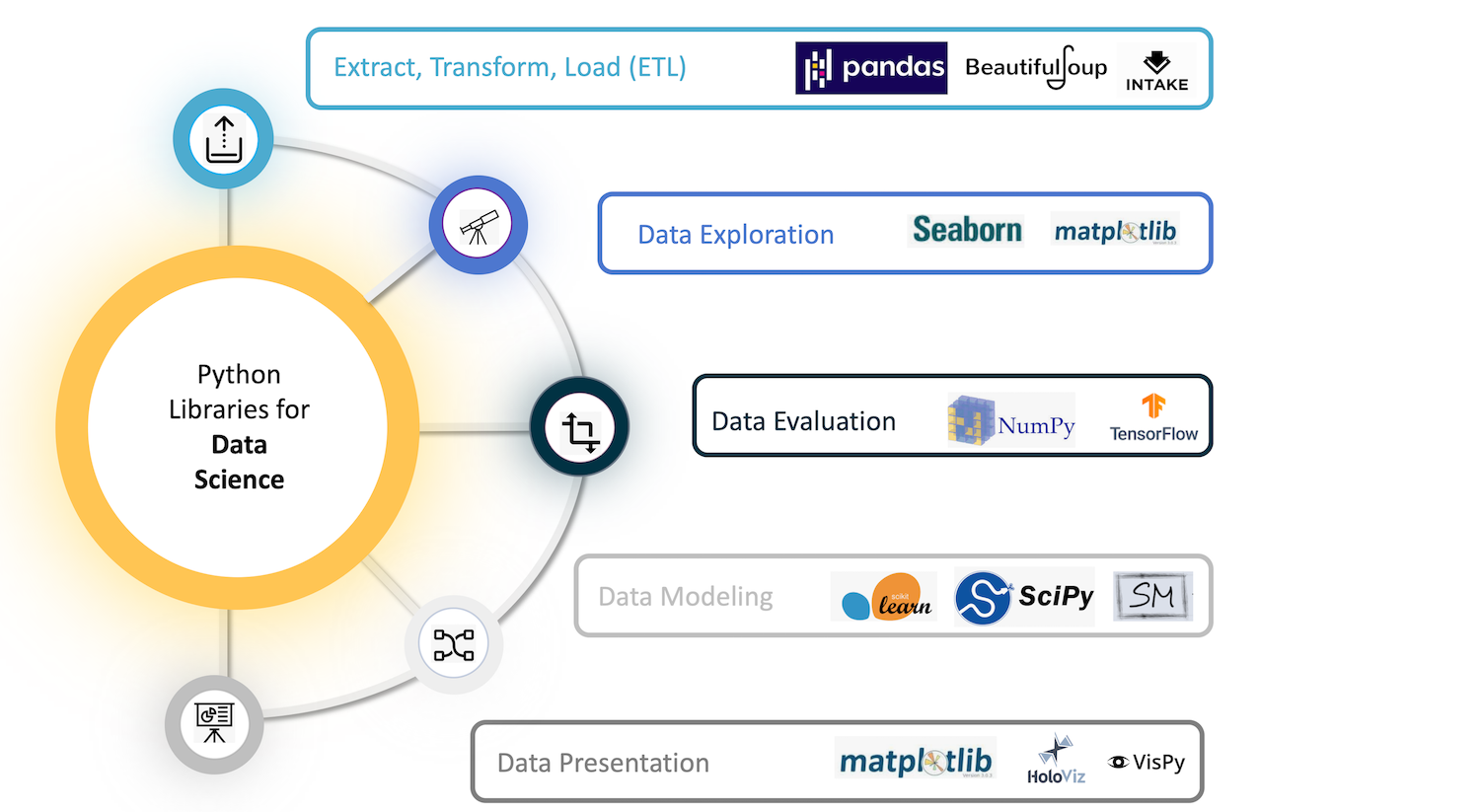
NumPy는 풍부한 데이터 과학 라이브러리 생태계의 핵심에 있습니다. 일반적인 탐색적 데이터 과학 워크플로는 다음과 같습니다.
NumPy는 scikit-learn 및 SciPy와 같은 강력한 기계 학습 라이브러리의 기반을 형성합니다. 기계 학습이 성장함에 따라 NumPy에 구축된 라이브러리 목록도 늘어납니다. TensorFlow의 딥 러닝 기능은 폭넓게 응용할 수 있습니다. — 그 중에는 음성 및 이미지 인식, 텍스트 기반 애플리케이션, 시계열 분석 및 비디오 감지가 있습니다. 또 다른 딥 러닝 라이브러리인 PyTorch는 컴퓨터 비전 및 자연어 처리 연구자들 사이에서 인기가 있습니다. MXNet은 딥 러닝을 위한 청사진과 템플릿을 제공하는 또 다른 AI 패키지입니다.




몇 가지만 예를 들자면 NumPy는 Matplotlib, Seaborn, Plotly, Altair, Bokeh, Holoviz, Vispy, Napari, PyVista 등이 포함되어 있으며 급격히 성장해나가고 있는 Python visualization landscape의 핵심 구성 요소 중 하나입니다.
NumPy는 큰 배열을 고속으로 처리할 수 있어 연구자가 기존 Python이 처리할 수 있는 데이터셋보다 훨씬 큰 것도 시각화할 수 있도록 합니다.